设为首页
收藏本站
开启辅助访问
搜索
热搜:
微信
电子商务
本版
文章
用户
首页
业务
新闻
解决方案
关于我们
帮助中心
客服中心
QQ登录
微信登录
注册
|
登录
客服中心
工单中心
网站建设
服务器代维
微信公众号
公司新闻
行业动态
会员社区
易企云站
[公告专区]
网站主页下方需注明已获得的备案编号通知
[公告专区]
关于域名实名认证的重要通知
[微信公众号]
1212
[微信公众号]
微信连Wi-Fi插件对所有公众号开放
[网络技术]
中英文导航台提交网址URL
[网络技术]
dz怎样优化?
Chrome 将警告用户不
阿里云发布小程序繁星
小程序分享及用户信息
企业微信宣布接入小程
塞凌云-爱企业
»
社区
›
交流区
›
杂谈
›
如何判断出网页被Google判断为复制内容呢?
返回列表
发布主题
如何判断出网页被Google判断为复制内容呢?
[复制链接]
查看:
1757
|
回复:
0
冷暖
当前离线
积分
19
冷暖
发表于 2014-4-16 21:32:35
|
显示全部楼层
|
阅读模式
Google在其官方的GoogleWebmasterCentral博客上发布了一篇文章,最主要的内容即是:假如你的某个页面因为被Google判别为仿制内容而致使不在查找成果中显现,那么你会收到一封提示信息,这样你就晓得你这个页面为啥死活木有排行了,并且假如你看到这样的音讯之后,发现这篇文章肯定是你自个的自创,是Google判别过错了,那么你还能够提出申述。
" T& @+ q" ^+ B4 {
文章称,假如Google发现了一组包括重复内容的页面,就会运用算法从这组页面中选出一个最具有代表性的作为“规范页面”,这组包括重复内容的页面有能够是来自不一样的域名,Google将这种在不一样域名下的页面中挑选规范页面称为“跨域URL选择”。
s3 y$ u4 c' c3 d4 G8 Q
关于重复页面,有许多的解决办法,最简单最合理的是运用rel=canonical标签。但是并非一切网站一切者都会关怀重复页面的疑问,假如站长疏忽了这一点,没有运用任何方法标记出一个规范页面,那么Google就会自个进行判别,这也就意味着判别呈现差错,这即是为何有时分站长发现自个希望被Google录入并给予排行的页面偏偏即是比不上一个自个并不在乎的页面。
+ F" [1 V$ \5 f7 I
这个新功能的呈现,使得网站一切者能够很清晰的晓得自个的某个页面是不是被Google用其它页面乃至其它域名的页面给替代了,一般以下几种状况会致使你的页面被其它页面乃至另外域名的页面替代。
' n/ t) B5 D+ H
网站一切者自个规则了一个“规范页面”,比方运用“rel=canonical”规则了一个规范页面,那么Google在判别之后,也会提示你,主要是用于承认你的设置。
7 Y7 x# x8 V9 X2 ^7 S
假如你的网站有同名的国别站,比方domain, domain.co.uk, domain.de,那么这些网站上的同一篇文章会被判别为重复内容,不过Google会依据查找者所运用的语言展现对应语种的规范页面,也即是说,假如一个英国用户查找这个关键字,那么Google就会将 domain.co.uk这个域名下的文章页面作为规范页面回来给查找者。
+ K. \5 V: U. d- v
假如网站一切者在运用rel=canonical时因为疏忽,将规范URL指向了一个本站之外的页面,Google仍然会遵从这个设置用指向的那个本站之外的页面替代站长希望运用的规范页面,好在站长也会收到这么一则提示。
- r) ]1 \% h9 h9 U$ q; w! f( ]' }( Y
有些服务器(一般是共用的服务器)疑问会致使同一个页面发生两个乃至多个不一样的URL,这时Google Bot会依照算法主动进行判别,也就有能够致使判别过错,这种状况呈现的几率十分小。
: F- i2 R) V3 ^' ^8 q! a# ?
黑进犯,在你的网站上挂上恶意代码,使蜘蛛访问时主动跳到其它网站上去,会致使Google判别出的规范页面与你所希望的规范页面不一样。
G9 [: k s/ p& g! Q2 n3 o
即使不呈现以上的几种状况,Google在自个进行判另外时分,也有能够过错的将另外页面判别为规范页面,而实际上这个Google判另外规范页面的内容是从你的网站仿制曩昔的。不过文章中也着重,这种状况呈现的几率微乎其微。
2 I9 ~3 F$ J s/ {% Q( Q
回复
举报
返回列表
高级模式
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
加入爱企业
本版积分规则
发表回复
回帖后跳转到最后一页
热门产品
微信连Wi-Fi插件对所有公众号开放
为了让更多商户享受微信连WiFi服务,现允许非认证公众号开通微信连Wi-Fi插件。 所
爱企业
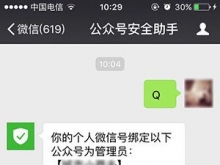
公众号绑定运营者查询
如何查询微信号已绑定的公众号运营者? 第一步:关注公众号“公众号安全助手”;
千寻
如何使用微信管理易企云站
1、关注微信公众号“爱企业云服务”; 2、绑定微信登录(点击查看); 3、点
爱企业
阿里云发布小程序繁星计划 20亿元补贴开发
3月21日上午,2019阿里云峰会在北京举行,阿里云回顾了过去十年的业绩,还发布了数十
木木
.top域名注册局维护通知
尊敬的用户: 您好! 接到注册局维护通知:将于北京时间2015年9月21日凌晨00:15
爱企业
快速回复
返回顶部
返回列表